Un compilateur complet comprend un certain nombre de phases, disons optionnelles, de niveau sémantique (c’est à dire qui s’appliquent au langage source), il s’agit d’abord de la vérification des types (ou de vérifications plus simples du bon usage des noms, souvent effectuées à l’occasion du typage), mais aussi d’optimisations de haut-niveau reposant sur la sémantique du langage et idéalement appliquées à l’arbre de syntaxe abstraite. Je ne détaillerai pas ces phases optionelles, le typage est déjà traité dans le cours langage et programmation de majeure I.
Dans le chemin de la syntaxe concrète au code machine, la phase « sémantique » pourrait a priori être toute la traduction de la syntaxe abstraite vers le code machine : un sens est donné au langage à l’aide des moyens d’expression de la machine. Pour des raisons de bonne compréhension et de souplesse on ne produit pas directement du code pour la machine ciblée. On se donne un code dit intermédiaire qui est le code d’une machine idéale et on produit du code pour cette machine.
Toutes les opérations sémantiques ont besoin de réaliser les règles de résolution des reférences de variables. C’est à dire qu’elles doivent savoir définir une liaison entre une variable et quelque chose et retrouver le quelque chose plus tard au vu du nom de la variable. Il est logique de regrouper l’ensemble des fonctionnalités liées aux environnements dans un module idoine dénommé Env, afin de les offrir à toutes les phases sémantiques, mais aussi pour bien structurer notre code.
Dans les langages compilés les liaisons des variables sont réalisées selon le principe de la portée lexicale. Prenons un exemple (en Caml) :
| let x = "coucou" in x ^ (let x = 1 in string_of_int (x+1)) ^ x) |
Les occurences des variables dans les expressions (dites non-liantes) font référence à la liaison (les occurrences liantes) la plus proche en regardant vers le haut (dans l’arbre de syntaxe abstraite).
Du point de vue de la gestion des environnements l’évaluation de l’expression ci-dessus demande de (évaluation de la gauche vers la droite) :
x ^,
string_of_int (x+1),
^ x.
Autrement dit (et c’est un peu plus abstrait) :
string_of_int (x+1) est évalué dans un environnement où
x vaut 1.
x ^ et ^ x sont évalués dans un environnement où
x vaut "coucou".
Notons qu’à l’exécution du code compilé, rien n’oblige à détruire l’espace mémoire réservé à la seconde liaison de x en même temps que la destruction de la liaison correspondante, ou à l’allouer en même temps que sa création. La politique « lexicale » s’applique aux liaisons uniquement. On peut la réaliser selon principalement deux schémas, d’abord un schéma impératif ou un schéma plus fonctionnel (au sens de langage fonctionnel).
exception Free of string (* en cas de référence à une variable non liée *) let env = Hashtbl create 17 let get x = try Hashtbl.find env x with Not_found -> raise (Free x) let set x v = (* récupérer l'ancienne valeur de x *) let old_v = try Some (get x) (* x avait une valeur *) with Free _ -> None in (* x n'etait pas lié *) (* creation d'un liaison de x à v, qui efface la précédente *) Hashtbl.replace env x v ; (* renvoyer l'ancienne valeur de x *) old_v let restore x old_v = match old_v with | None -> Hashtbl.remove env x (* détruire la liaison de x *) | Some v -> Hashtbl.replace env x v (* restaurer la liaison de x *)
Un premier schéma impératif utilise les tableaux associatifs On peut les voir comme des tableaux ordinaires dont les indices ne sont pas forcément des entiers consécutifs (ici ce sont des chaînes). La figure 6.1 décrit la réalisation de cette structure de données à l’aide de tables de hachage (module Hashtbl). Nous avons d’abord besoin d’une opération pour accéder à une association (fonction get), et d’associer un nom de variable à une valeur (fonction set). Mais, lorsque set range la valeur v dans la case x, il détruit irrémédiablement ce qui s’y trouvait avant. Je propose donc que set renvoie l’ancienne valeur de cette case, si elle existait, ainsi qu’une dernière fonction restore pour la remettre dans sa case le temps venu. Pour traiter le cas sans liaison pré-existante (que les tables de hachage révèlent), j’utilise le type option du module « ouvert par défaut » Pervasives.
Voyons donc comment utiliser ce style d’environnements dans un interprète, on aura :
| let rec eval = function | Var x -> get x | Let (x, ex, e) -> let vx = eval ex in let old_vx = set x vx in let ve = eval e in restore x old_vx ; ve | ... |
C’est un peu compliqué et source d’erreurs idiotes (oublier restore par exemple), on souhaiterait dans un esprit plus fonctionnel, passer l’environnement à l’évaluateur et evaluer les expressions en fonction des environnements (c’était l’idée des interprèteurs du chapite 3). On alors besoin d’une fonction extend pour créer une liaison et toujours d’une fonction get. Le plus simple est alors de ne pas détruire une ancienne liaison par une nouvelle mais de la cacher, l’ancienne liaison existe toujours, mais elle n’est plus accesssible. Une première réalisation à base de listes de couples (module List) est vite programmée :
| (* On pourrait utiliser List.assoc qui fait la même chose *) let rec get x env = match env with | [] -> raise (Free x) | (y,v)::rem -> if x=y then v else get x rem let extend x v env = (x,v)::env |
L’utilisation de tels environnements est bien plus simple (et moins dangereuse) que celle des environnement impératifs :
| let rec eval env = function | Var x -> get env x | Let (x, ex, e) -> let vx = eval env ex in eval (extend x vx env) e | ... |
Le principal désavantage de cette technique est que les get sont assez inefficaces (de l’ordre de la taille des environnements). Heureusement il existe des associations de style fonctionnel plus efficaces (en log de la taille des environnements), réalisées à base d’arbres équilibrés. Elles sont disponibles dans la bibliothèque standard de Caml dans le module Map. L’utilisation du module Map illustrée par la figure 6.2 est un rien complexe, car il faut appliquer un foncteur, c’est à dire une sorte de fonction des modules dans les modules.
(* Module des chaînes ordonnées *) module OrderedString = struct type t = string let compare s1 s2 = Pervasive.compare s1 s2 (* ordre standard *) end (* Application du foncteur, pour créer le module des associations aux chaînes *) module StringMap = Map.Make OrderedString let get x env = try StringMap.find x env with Not_found -> raise (Free x) let extend x v env = StringMap.add x v env
Dans un programme, tous les noms ne sont pas à comprendre de la même façon et deux noms identiques peuvent faire référence à des entités distinctes selon le contexte de leur utilisation. Les noms se classent par catégories disjointes. Par exemple, en Pascal une fonction et une variable peuvent avoir le même nom (mais pas en Caml, où les fonctions sont des valeurs du langage comme les autres). En général, champs d’enregistrements, variables normales et variable désignant des types appartiennent à des espaces de noms différents.
Tous ces noms correspondent à des liaisons traitées sur le mode lexical ou parfois sur un mode global (fonctions de Pseudo-Pascal) selon des modalités qui changent d’un espace de nom à l’autre. Considérons par exemple le cas de Pseudo-Pascal :
Nous pouvons maintenant préciser l’interface de notre module des environnements de Pseudo-Pascal (figure 6.3).
type ('a, 'b) environment (* type des environnement qui associe aux variables des valeurs de type 'a et aux fonctions des valeurs de type 'b *) exception Free of string (* retourne l'identificateur recherché lorsqu'il n'est pas trouvé *) val create_global : (string * 'a) list -> (string * 'b) list -> ('a,'b) environment (* "create_global v d" crée un environement avec les liaisons globales v et les définitions d. Sur une telle table, find_var x retournera la valeur de la liaison x dans v et find_definition x la valeur de la définition x dans d. *) val add_local_vars : ('a,'b) environment -> (string * 'a) list -> ('a,'b) environment (* ajoute des liaisons locales à un environement *) val change_local_vars : ('a,'b) environment -> (string * 'a) list -> ('a,'b) environment (* remplace les liaisons locales *) val find_var : ('a,'b) environment -> string -> 'a val find_definition : ('a,'b) environment -> string -> 'b (* "find_var env x" recherche la valeur de x dans les liaisons locales ou globales de env. "find_definition env x" recherche la valeur de x dans les definitions de env. *)
Notons d’abord que le type environment des environnements est
paramétré (par 'a et 'b).
En effet le module Env est utile pour toutes les
phases sémantiques qui en ont besoin et n’associent pas toujours les
mêmes valeurs aux fonctions et aux variables « normales ».
Par exemple, un typeur souhaitera associer des types, un interprèteur
des valeurs du langage source.
Les deux catégories de noms incitent à proposer deux fonctions d’accès
différentes, une pour les variables, une pour les fonctions.
La règle de formation des environnement au début du monde est donc
de créer toutes les liaisons des fonctions et des variables
globales et la règle à appliquer dans les corps de fonctions
est donc de mettre à jour les liaisons locales uniquement.
Selon le contexte (on souhaite conserver les anciennes liaisons
locales ou pas) on utilisera add_local_vars ou
change_local_vars.
Le code qui réalise cette interface ne sera pas commenté.
En particulier son type est abstrait, son nom
(environment) apparaît dans l’interface, mais pas sa
définition. Disons juste
qu’il s’agit d’un enregistrement à trois champs, chaque champ étant
une table d’associations de style fonctionnel (definie par ailleurs).
Disons aussi que la fonction
find_var, cherche d’abord parmi les liaisons locales,
puis en cas d’échec parmi les liaisons globales, comme le revèle un
extrait de l’implémentation env.ml :
| type ('a, 'b) environment = { definitions : 'b table; global_vars : 'a table; local_vars : 'a table; } ... let find_var env x = try get x env.local_vars with Free _ -> get x env.global_vars |
Quelque soit la sophistication du langage compilé, les environnements sont gérées d’une façon similaire. Par exemple dans le cas de Pascal (avec des fonctions locales), il faudra prévoir d’étendre aussi la partie definition des environnements. La plus grande complication prévisible provient de la compilation séparée moderne, nos uniques tables des globaux et des fonctions, disparaissent au profit d’une table des modules, association entre les noms de modules et les tables qui les décrivent. Un environnement « global courant » contient les entitées définies par le module en cours de compilation. Notez que cet environnement « global courant » se construit aussi à partir des tables des modules « ouverts » (construction open en Caml).
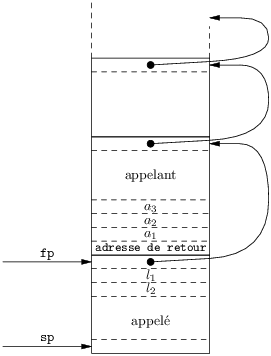
Plus tard, lors de l’exécution les variables ont disparu en tant que concept. Elles sont essentiellement remplacées par des cases dont le contenu est la valeur de la variable. Ces cases sont de deux sortes : des cases de la mémoire ou des registres du processeur.
En oubliant pour le moment les registres et en se restreignant à la compilation de Pseudo-Pascal, l’allocation des cases mémoire devient assez simple :
En fait, le compilateur peut la plupart du temps connaître la taille maximum de pile occupée par le frame d’une fonction. Il suffit a priori, si le langage n’autorise pas d’allocation arbitraire en pile (cf. alloca de C), de regarder le corps de la fonction. Le code d’une fonction peut donc allouer la totalité de son frame dès le départ de ne le rendre qu’avant de revenir. Dès lors, fp est inutile (il vaudra toujours sp plus la taille du frame) et c’est ce que nous allons faire dans ce cours. Mais cette organisation de la pile avec deux registres est toujours utilisé :
La recherche de l’efficacité conduit à essayer d’attribuer le plus possible des registres aux variables. Prenons quelques exemples :
Pour bien exploiter les registres un compilateur a besoin d’informations sur l’usage des variables. Une simplification considérable est de limiter les analyses nécessaires au corps des fonctions, analysées indépendamment les unes des autres. C’est plus simple, moins coûteux, et les résultats sont déjà très bons. Notons aussi que l’interaction avec des fonctions compilées par ailleurs (et surtout avec celles qui ont été compilées par un autre compilateur) commande d’adopter des conventions fixées au sujet des variables globales et des paramètres. Ces conventions anullent la liberté de mettre variables globales et paramètres formels dans des registres arbitraires. Dans le cas RISC, les conventions d’appel commandent le plus souvent de mettre les paramètres dans des registres convenus, ce qui suffit pour déjà bien profiter des nombreux registres du processeur.
Bref, les environnements sont bien gérés en allouant un frame de pile à chaque appel, mais les décisions de mettre telle variable (ou paramètre) en pile ou en registre sont prises en aval de la génération de code intermédiaire. Nous allons voir comment dans la suite du cours.
Le code intermédiaire constitue d’abord une interface claire entre le langage et la machine. Son existence augmente la souplesse des compilateurs qui se divisent alors clairement en deux :
Dans l’idéal, on peut combiner divers back-ends et front-ends comme on le souhaite. Ainsi si on dispose de deux front-ends, un pour C et un pour Fortran, et de deux back-ends, un pour Mips et un pour Pentium on dispose de quatre compilateurs complets. En pratique, c’est la définition du code intermédiaire qui limite l’intérêt de ces combinaisons, car il doit être suffisamment expressif pour exprimer toutes les constructions des langages sources, mais aussi suffisamment proche des machines réelle pour que les back-ends ne ressemblent pas à des compilateurs complets et surtout qu’ils produisent du code efficace.
Un effet intéressant du code intermédiaire est l’effet unificateur de sa concision. Diverses constructions (voisines) du langage source s’expriment par la même construction du code intermédiaire (appel de fonction et de procédure par exemple), tandis qu’une même construction du code intermédiaire peut regrouper deux opérations voisines de l’assembleur (addition d’une variable entière et d’une constante, ou calcul de l’adresse d’une case de tableau par exemple). Tout travail effectué sur le code intermédiaire est donc très bénéfique, car il factorise un travail qui devrait autrement s’effectuer sur plusieurs constructions distinctes. Évidemment tout travail reposant directement sur la sémantique du langage source (le typage par exemple, ou une optimisation de « haut-niveau ») sera mieux fait en amont, et tout travail reposant beaucoup sur un trait spécifique de la machine ciblée (utilisation d’instructions complexes par exemple) sera mieux fait en aval.
Le point de vue équilibré de la combinaison arbitraire des front-ends et des back-ends concerne a priori les industriels qui vendent des compilateurs, leur intérêt est bien entendu de proposer le plus de compilateurs possibles pour un travail minimum. On doit aussi considerer le cas des industriels qui produisent des processeurs, leur intérêt est de proposer beaucoup de langages bien compilés sur leur machine. S’ils sont malins, il construiront à grand prix un back-end très efficace et acceptant un langage intermédiaire plutôt d’assez haut-niveau, pour rentabiliser leur énorme investissement. Ils doivent prendre garde à ne pas proposer un code intermédiaire trop proche de leur machine, et donc lutter contre la tentation de mettre en avant les traits distinctifs de leur nouveau processeur.
Les concepteurs de langages de programmation ont un objectif qui semble opposé. Ils souhaitent compiler leur langage, et pouvoir cibler plusieurs machines (car ils souhaitent diffuser leur langage le plus possible). Bizarrement, s’ils sont malins, leur code intermédiaire sera aussi d’assez haut-niveau, (mais ils auront tendance à l’adapter à leur langage). En effet, la compilation efficace demande un gros travail à cause des capacités d’expression limitées des machines et ce travail ne change pas fondamentalement d’une machine à une autre. Il est donc avantageux de procéder à ce travail par transformation du code intermédiaire et de ne se décider pour une machine donnée que le plus tard possible.
type exp = Const of int (* Entiers et Booléens *) | Name of Gen.label (* Adresse mémoire nommée *) | Temp of Gen.temp (* Lecture d'un temporaire *) | Mem of exp (* Lecture mémoire *) | Bin of binop * exp * exp (* Opération binaire *) | Call of Frame.frame * exp list (* Appel de fonction ou appel système *) and stm = | Label of Gen.label (* Étiquette (dans le code) *) | Move_temp of Gen.temp * exp (* Écriture dans un temporaire *) | Move_mem of exp * exp (* Écriture en mémoire *) | Seq of stm list (* Séquence d'instructions *) | Exp of exp (* Expression évaluée pour son effet *) | Jump of Gen.label (* Saut non conditionnel *) | Cjump of (* Saut conditionnel *) relop * exp * exp * Gen.label * Gen.label and relop = Req | Rne | Rle | Rge | Rlt | Rgt and binop = Uplus | Plus | Minus | Times | Div | Lt | Le | Gt | Ge | Eq | Ne (* Uplus est l'addition non signée pour les calculs d'adresses *) type code = stm list
Il représente en quelque sorte ce que tous les processeurs (ciblés, soyons modestes) ont en commun, sans nous engager trop à cause de ce qu’ils ont de différent. Le type Caml du code intermédiaire est donné par la figure 6.5.
Les points 1, 3, 4, et 5 traduisent que nous ciblons un processeur, qui exécute des instructions les unes après les autres (certaines de ces instructions sont des branchements) et qui sait faire la différence entre un registre et la mémoire.
Les points 2, 6 et 4 expriment que nous ne souhaitons pas nous engager dès maintenant, ni sur la traduction des expressions en instructions machine, ni sur la traduction des appels de fonctions (car ils dépendent fortement de la machine ciblée), ni sur le nombre réel de registres et surtout sur leur usage (passage d’arguments, callee-save, etc.) Il faut bien comprendre que nous pourrions être plus explicites et adopter une représentation plus proche d’une machine réelle. Mais le code produit au final exploiterait mal certaines potentialités offertes par un processeur en particulier et serait inefficace.
Plus précisément, les choix des branchements et du code linéaire pour les instructions ne nous limitent pas outre mesure dans notre choix de machines cibles. En revanche, le nombre infini de registres insensibles aux appels de fonction rend compte que nous ciblons des machines dont nous espérons pouvoir bien exploiter les registres. Par exemple, le compilateur décidera plus tard de ranger une variable locale dans la pile, si elle doit survivre à un appel de fonction. Si nous ciblions exclusivement des processeurs avec très peu de registres, une telle complication serait inutile, et nous pourrions dès maintenant décider de mettre toutes les variables locales en pile, mais alors nous serions incapable de produire du code efficace pour les processeurs qui ont beaucoup de registres.
Passons maintenant en revue l’environnement de notre code intermédiaire. Les étiquettes et les temporaires doivent être tous distincts, la figure 6.6 donne un extrait de l’interface du module Gen qui fournit un type abstrait des étiquettes et quelques fonctionnalités de base.
(********************) (* Les étiquettes *) (********************) type label (* Renvoie une nouvelle étiquette *) val new_label: unit -> label (* retourne une étiquette avec le nom passé en argument. Échoue si une étiquette de ce nom existe déjà *) val named_label : string -> label (* idem, mais ajoute un suffixe si le nom existe au lieu d'echouer *) val prefixed_label : string -> label (* Pour afficher les étiquettes, dans l'assembleur final par exemple *) val label_string : label -> string
Le module Gen fournit des fonctionnalités similaires pour les temporaires. La génération de code crée beaucoup de temporaires, mais l’allocation de registres qui vient en aval saura très bien les transformer en registres réels, et les temporaires dont la durée de vie est très courte n’auront pas besoin d’être sauvegardés en pile. Donc il faut se retenir de tenter « d’optimiser » l’usage des temporaires dès maintenant. Au contraire, plus on en crée, plus leur durée de vie sera courte et plus facilement ils pourront partager le même registre plus tard. Le mode de pensée à adopter est à l’opposé de celui du programmeur débutant qui a tendance à réutiliser ses variables…
Un autre module, Frame, entend d’abord définir la représentation en machine des fonctions, donnée par le type abstrait frame, dont on peut noter qu’il est argument de l’expression Call (cf. la figure 6.5). Comme cette représentation dépend de la machine ciblée, un certain nombre de détails qui en dépendent directement sont également fournis par le module Frame, comme la taille des mots en octets (4 pour le MIPS) donnée par une variable word_size. Ce module sera détaillé en temps utile.
Générer un bon code intermédiaire en une seule passe est assez obscur, on va diviser cette opération en trois passes, d’abord générer du code sans soucis d’efficacité ni d’adaptation à la génération de vraies instructions machines, puis corriger cela dans les passes suivantes de linéarisation/canonisation et d’optimisation du flot de contrôle :

Cette division en petites étapes, où une passe introduit des inefficacités corrigées par une autre en aval, est robuste, modulable et elle favorise la généralité (et donc la réutilisabilité du code des modules du compilateurs). Un autre avantage est que les passes optmisantes corrigent les inefficacités présentes dans le source en plus de celles introduites par les passes précédentes. Ces avantages compensent plus que largement la relative lenteur du compilateur, surtout à notre époque. La division du back-end en deux (génération du code intermédiaire, puis du code machine) et d’ailleurs un autre exemple du même principe.
On traduit récursivement les expressions et les instructions de Pseudo-Pascal (module Pp), en expressions et instructions du code intermédiaire (module Code) Nous notons ces traductions respectivement [[ _ ]]ρe et [[ _ ]]ρs. On notera que les traductions sont paramétrées par un environnement ρ.
La traduction des expressions constantes est triviale, remarquons tout de même que les booléens disparaissent au profit de leur realisation par les entiers machines.
| [[Int n]]ρe = Const n [[Bool true]]ρe = Const 1 [[Bool false]]ρe = Const 0 |
Opérations binaires et séquences de Pseudo-Pascal se traduisent dans les mêmes constructions présentes dans le code intermédiaire.
|
La traduction des constructions de tableaux (lecture, écriture) expose les accès à la mémoire. Notons qu’elle est simple parce que les tableaux de Pseudo-Pascal sont sémantiquement des références, et sont donc réalisés par des adresses mémoire. Le calcul de l’adresse de la case d’indice i fait intervenir la taille (en octets) des valeurs rangées dans le tableau (t + w * i, où t est l’adresse du tableau). En Pseudo-Pascal, toutes les valeurs occupent un mot machine, w est donc une constante dépendant seulement de la machine ciblée (en pratique ce sera 4 ou 8). Dans le cas géneral cette taille se calcule à partir des types.
|
On notera l’emploi de l’addition non-signée, en fait aucun processeur raisonable ne produit des résultats différents pour une addition signée ou non signée (c’est une bonne propriété de la représentation des entiers en machine par complément à deux). La différence apparaît en cas de débordement, qui est signalé différemment dans les deux cas. La vaste majorité des langages ignorent cette question de débordement et donc peuvent confondre les deux additions, ils ne peuvent pas faire de même pour les comparaisons qui elles produisent des résultats différents dans les cas signé ou le cas non-signé. Or C, par exemple, autorise la comparaison des adresses. Nous ne pouvons donc pas ignorer cette question de signe et l’addition non-signée nous sert d’exemple. Il faut retenir que le meilleur endroit pour introduire la distinction est le code intermédiaire.
La conditionnelle se traduit nécessairement en plusieurs instructions élémentaires, on triche un peu en utilisant la séquence comme une instruction. Lorsque la condition est un test simple, c’est à dire une comparaison d’entiers (<, ≤, etc.), il convient de court-circuiter la sémantique d’opérateur à valeur booléene, afin d’utiliser directement les instructions test-and-branch des machines. On notera que le test-and-branch du code intermédiaire spécifie deux adresses, il faut brancher vers la première si la condition est vérifiée et vers la seconde si la condition est invalidée. Cette instruction bizarre laisse une grande liberté de réorganiser le code par la suite.
|
Les tests complexes se traduisent facilement en considérant le résultat nécessairement booléen de la condition et un test simple (ici e1 différent de false, selon la convention adoptée par la sémantique de C).
| [[If (e1, st, sf)]]ρs = [[If (Bin (Ne , e1, Const 0), st, sf)]]ρs |
La traduction de la boucle while est similaire.
|
Attaquons nous d’abord aux accès aux variables, nous verrons plus tard comment les liaisons sont créées. Absolument toutes les variables locales et tous les paramètres formels sont rangées dans des temporaires (rapellons que les temporaires représentent à la fois les registres et des cases dans la pile). Les variables globales résideront en mémoire (mais en mémoire statiquement allouée). L’environnement ρ doit donc associer les noms des variables à un temporaire ou à une adresse mémoire. Dans le premier cas, ρ(x) est un temporaire t et on a les traductions évidentes.
|
Dans le second cas, ρ(x) est une addresse mémoire a et on a encore les traductions évidentes.
|
On note que l’accès en lecture examine le contenu de l’adresse, tandis
que l’écriture prend cette adresse en argument. Ainsi une variable à
gauche ou à droite d’une affectation n’a pas la même interprétation.
Dans les langages impératifs (C, Pascal) cette subtile distinction
amène une confusion quand on cherche à comprendre le sens des
expressions pouvant se trouver à gauche et à droite d’un signe
d’affectation (= ou :=), c’est à dire principalement
d’une variable x, d’un accès dans un tableau
t[i], ou surtout d’un déréférencement de pointeur
(*p ou p^).
Dans le premier cas (à gauche) il faut voir l’expression comme
le calcul d’une adresse dont on modifie le contenu,
dans le second cas il faut comprendre l’expression
comme le le contenu de la même adresse.
En Pseudo-Pascal la difficulté apparaît moins clairement, car la
syntaxe abstraite distingue les deux utilisations autorisées de
l’affectation, et les tableaux sont des références.
En conséquence, les expressions sont toujours des contenus, y compris
dans Geti (e, _) et Seti (e,
_, _) (qui sont respectivement e[_]
et e[_] :=_).
Le cas de la compilation des appels de fonctions est semblable en esprit à celui des variables, les fonctions de Pseudo-Pascal sont désignées par un nom (qui a sa propre catégorie dans l’environnement). L’environnement lie les noms des fonctions à des structures spécifiques les frames, que l’instruction d’appel du code intermédiaire prend justement en argument. Nous avons donc, pour les procédures et les fonctions, en notant F le frame de f.
|
Le traitement des appels de primitives est le même, à la différence que leur frame n’est pas dans l’environnement ρ, mais défini comme une valeur du module Frame (Frame.frame_write, etc. voir la section 6.3.4). Si les primitives étaient très nombreuses il faudrait sans doute trouver un autre arrangement utilisant un environnement des primitives. Il faudrait alors faire attention aux redéfinitions des noms des primitives.
Il nous reste à voir comment les temporaires, adresses mémoire et frames sont introduits dans les environnements. Commençons par le cas le plus simple des variables globales. On doit, au début du monde et pour chaque variable globale allouer statiquement un mot de mémoire. (une fois encore, si les valeurs du langage n’occupent pas toutes un mot mémoire l’espace alloué dépend du type de la variable). Ensuite, on doit repérer cette addresse, une technique simple est de la repérer par une étiquette, puis d’associer le nom de la variable globale à l’étiquette. Cette technique ne convient pas aux processeurs RISC que nous ciblons (parce que le chargement d’une adresse arbitraire dans un registre prend de l’ordre de deux instructions machine). On repère donc plutôt une variable globale par rapport à une adresse particulière qui est par exemple celle du début de la zone mémoire des globaux. Cette adresse sera chargée dans un registre gp (désigné par le temporaire Frame.global_register) au début de l’exécution. Donc l’adresse de la i-ème variable globale sera :
| Uplus (Const (w*(i−1)), Temp gp) |
En Pseudo-Pascal, les variables locales sont introduites exclusivement au début des fonctions (et des procédures, c’est presque pareil). La création des liaisons correspondantes se comprend mieux en exposant comment les fonctions sont compilées.
Conformément à l’idée de ne pas trop nous engager au sujet des
registres et de la mémoire allouée en pile,
nous allons associer un temporaire frais à chaque variable locale
(ie. un temporaire obtenu par un appel à Gen.new_temp).
Mais ce n’est pas tout ! Nous refusons aussi de nous engager sur le l’emplacement des arguments. Ainsi, pour une procédure à m arguments nous créons m nouveaux temporaires, et nous ajoutons aussi les liaisons correspondantes à l’environnement avant de compiler le corps. C’est une phase en aval entièrement dépendante de la machine ciblée (la sélection d’instructions) qui produira le code qui va chercher les arguments là ou l’appelant les y a mis pour le mettre dans les temporaires associés aux arguments. (Dans le cas du MIPS l’appelé trouve ses quatre premiers arguments dans les registres a0 à a3 et les autres sur la pile, mais le générateur de code intermédiaire ne doit surtout pas le savoir.) Dans le cas d’une fonction (par opposition à une procédure), un temporaire frais est également créé pour correspondre à la variable implicite contenant le résultat de la fonction. La sélection d’instructions produira du code pour transférer le contenu du temporaire associé au résultat là où l’appelant l’attend (pour le Mips, dans le registre v0). Ces deux bouts de code produits en aval, se nomment respectivement prologue et épilogue de la fonction, ils seront placés au début et à la fin du code de la fonction.
La type frame décrit les fonctions dans le back-end. C’est le point de rendez-vous idéal pour les diverses phases du back-end. Voici enfin la définition de ce type extraite de frame.ml :
| type frame = { name : Gen.label; (* Point d'entrée *) return_label : Gen.label; (* Adresse de l'épilogue *) args : Gen.temp list; (* Temporaire des arguments *) result : Gen.temp option; (* Temporaire du résultat (ou rien) *) mutable mysize : int; (* Taille nécessaire sur la pile *) } |
Les deux premiers champs définissent d’abord l’adresse du code de la fonction (utile pour l’appeler) et de son épilogue (techniquement utile à la comunication dans le back-end). Viennent ensuite les temporaires des arguments et du résultat (absent pour les procédures), utiles nous l’avons vu pour communiquer entre le générateur de code intermédiaire et la selection d’instructions. Enfin le dernier champ donne la taille qu’il faudra consacrer à un appel de fonction sur la pile, cette taille est calculée par plusieures phases du back-end.
Le type frame des frames (blocs d’activation) est abstrait, impossible de travailler directement dessus, on devra passer par les fonctions du module Frame. Il y a plusieurs raisons à cela.
| val named_frame : string -> Pp.var_list -> Pp.type_expr option -> frame |
Bref, tout de qui concerne l’organisation intime des frames est
circonscrit au module Frame, afin de bien délimiter ce qui
change si cette organisation change.
Et nous connaissons maintenant la représentation d’une fonction à
ranger dans l’environnement : un frame, crée par un appel à
named_frame.
Le module Pp définit les fonctions comme un type enregistrement :
| definition = { arguments : var_list; result : type_expr option; (* arguments et type du résultat *) local_vars : var_list; (* variables locales *) body : instruction list; (* corps de la fonction *) } |
La compilation d’une fonction de nom f se passe donc en deux temps :
named_frame
auquel on passe f et les contenus des champs arguments et
result (de la définition des fonctions en syntaxe abstraite).
C’est cette fonction named_frame qui se charge de créer des
temporaires frais a1, a2, … , an pour les arguments
(et un temporaire r pour l’éventuel résultat), une
étiquette fraîche pour le point d’entre etc. et de ranger tout ça dans
le frame créé.
Toutes ces données seront rendues accessibles par le truchement de
fonctions idoines du module Frame et exportées dans son
interface. Dont voici un extrait pertinent :
| type frame (* Le type Frame.frame décrit les fonctions (sous-routines) du code intermédiaire *) val named_frame : string -> Pp.var_list -> Pp.type_expr option -> frame (* Creation du frame d'une fonction/procédure, dont le nom est passé en premier argument, les paramètres formels en second argument, et le (type du) résultat en dernier argument *) val frame_name : frame -> label (* retourne le point d'entrée de la sous-routine *) val frame_args : frame -> temp list (* retourne la liste des temporaires choisis pour recevoir les arguments *) val frame_result : frame -> temp option (* retourne le temporaire choisi pour retourner le résultat d'un vraie fonction, None pour une procédure *) val frame_return : frame -> label (* retourne l'étiquette choisie pour l'épilogue (marque la fin de la sous-routine *) |
| Seq [ [[s1]]ρs; …; [[sn]]ρs ] |
Frame.frame_name f, et on en sort par un saut
vers l’étiquette Frame.frame_return f, mais c’est encore
implicite.
Note culturelle
En Pascal, le corps d’une fonction f spécifie le
résultat à rendre en affectant une variable de nom f. Ce n’est pas
gênant puisque les fonctions et les variables « normales »
appartiennent à des catégories de noms distinctes. Cette convention
semble même assez maligne, mais à mon avis elle expose surtout la
technique de compilation dans le langage. C’est mal, la conception du
langage est inspirée par l’implémentation plutôt que par la recherche
d’une bonne expressivité. On comparera avec le return de C
et Java, bien plus pratique, et parfaitement réalisable selon le même
principe par des branchements vers l’épilogue
(étiquette Frame.frame_return f).
Dans notre compilateur les primitives (write, writeln,
alloc etc.) sont distinguées dans le front-end, au sens qu’elles
sont représentées par des nœuds particuliers de l’arbre de
syntaxe abstraite.
Cette distinction se justifie surtout dans le cas des primitives
alloc, dont le deuxième argument est un type justiciable d’une
analyse syntaxique bien particulière, et
et de read, dont l’unique argument est un nom de variable et pas
une expression générale.
Mais le code intermédiaire ne fait plus cette distinction, pour lui
les appels aux primitives sont des appels de fonctions ordinaires et
le primitives seront représentés par des frames comme toutes les
fonctions.
Ces frames particuliers sont fournis par le module Frame.
Voici l’extrait significatif du fichier d’interface frame.mli.
| (*************************) (* Frames des primitives *) (*************************) val write_int : frame val writeln_int : frame val read_int : frame val alloc : frame |
Dans notre compilateur, le code des primitives est en fait un bout d’assembleur qui sera ajouté plus tard à l’assembleur produit par le compilateur, lors d’une phase ultérieure de la compilation. Dans un compilateur plus realiste que le nôtre, les « primitives » seront bien plus nombreuses et assemblées (ou compilées si elles sont par exemple en C) indépendamemnt d’un programme quelconque. C’est alors le travail de l’éditeur de liens (et non plus du compilateur) d’aller chercher le code des primitives.
Une de nos primitives, read pose un petit problème. Il
faut maintenant la faire passer par le modèle des fonctions ordinaires
du code intermédiaire, alors qu’en Pseudo-Pascal, elle est speciale
puisque read x signifie lire un entier sur la console et
ranger sa valeur dans la variable x.
C’est à dire que l’appel à la prmitive read se compile grosso-modo comme
une combinaison d’affectation et d’appel de fonction.
Supposons par exemple que ρ(x) est un temporaire t, on a alors :
| [[read (x)]]ρs = Move_temp (t, Call (Frame.frame_read, [ ])) |
type 'a procedure = Frame.frame * 'a type 'a program = { number_of_globals : int; main : 'a procedure; procedures : 'a procedure list } val program : Pp.program -> Code.stm program
Tout au long du back-end (et donc désormais), Une procédure est une paire composée d’un frame et de quelque chose (ici d’un instructions de code intermédiaire, type Code.stm), et un programme est suffisamment décrit par le nombre de ses variables globales la liste de ses fonction et son point d’entrée (une fonctions aussi). Le type des procédures et des programmes est donc un type paramétré.
Il s’agit donc de transformer un programme de syntaxe abstraite (figure 6.8) en programme de code intermédiaire.
type program = { global_vars : var_list; (* variables globales *) definitions : (string * definition) list; (* fonctions et procédures globales *) main : instruction list; (* corps principal du programme *) }
La démarche de traduction du programme complet est donc :
C’est fini, le code est encore loin d’être exécutable, ni même de ressembler à du code machine (il est arborescent), mais il a été produit simplement. Comme la production de ce code réalise la sémantique du langage, cette simplicité est désirable : le programmeur du compilateur peut se concentrer sur le respect de la sémantique et non pas sur une hypothétique adéquation à la machine, d’ailleurs difficile à estimer à ce niveau.
S’il est un aspect qui est commun à toutes les machines connues, c’est bien que le code est une liste d’instructions. Or, l’instruction Seq du code intermédiaire lui donne une structure arborescente. Nous souhaitons donc la supprimer pour mettre tout le code à plat, ce qui semble assez facile. Cette exigence peut s’exprimer dans l’interface du module Canon, chargé (entre autres) de la linéarisation du code.
| val program : Code.stm Trans.program -> (Code.stm list) Trans.program |
Autrement dit, on change un programme (au sens de Trans, c’est à dire au sens du back-end) dont les fonctions sont des instructions du code intermédiaire, en un programme dont les fonctions sont des listes d’instructions du code intermédiaire.
Toutefois, nous voulons garder les expressions sous forme d’arbre car la selection d’instructions a besoin de ces arbres pour bien fonctionner. Plus précisément, en anticipant un peu, la sélection parcourt l’arbre d’une expression en produisant le code l’évaluant et rangeant le résultat du calcul dans un temporaire r. Or, à partir d’une expression Bin (Plus , e1, e2), la sélection peut a priori produire l’un ou l’autre de ces codes :
| Code qui calcule e1 dans r | Code qui calcule e2 dans r | |
| Code qui calcule e2 dans r′ | Code qui calcule e1 dans r′ | |
| ⇓ | ||
| r″ ← r+r′ | ||
Parfait, mais considérons cette expression :
| Bin (Plus , Call (f,e1), Call (g, (Call (h, e2))) |
La sémantique (évaluation de gauche à droite) impose le premier choix (code du premier argument d’abord), car les appels de fonctions peuvent faire des effets de bord (ici modifier des variables globales). La selection devra donc connaître un peu de sémantique et ce serait dommage, car elle serait plus compliquée et difficilement réutilisable dans un autre back-end. On peut aussi décider que l’ordre d’évaluation des arguments n’est pas spécifié dans la sémantique (C, Caml), j’aime bien cette solution, mais je ne peux plus changer la sémantique de Pseudo-Pascal maintenant. De toute façon, il y a un autre problème, bien plus grave, considérons cette expression :
| Call (f, Call (g, e1), Call (h, e2)) |
Supposons que les arguments sont passés en registres, arguments dans a0, a1, etc et résultat dans r0. Une des missions de la selection est justement de ranger les valeurs des paramètres effectifs dans ces registres. Alors (ordre gauche-droite), la sélection simple donnera ce genre de code :
|
Ça ne fonctionne pas, le passage de l’argument de h détruit le premier argument de de f en attente dans a0. On pourrait compliquer la sélection, mais encore une fois ce serait dommage, car il y a une sélection par processeur ciblé et nous ne voulons pas dupliquer nos efforts.
Le plus simple est de mettre le code intermédiaire sous forme canonique, ainsi définie.
Par exemple, (l’instruction Move_tmp est abrégé en Move ) :
| Seq [Move (t0, Bin (Plus , Call (f,e1), Call (g, (Call (h, e2))))) ; …] |
devrait être transformée en la suite d’instructions :
|
La transformation introduit beaucoup de temporaires, gardons confiance dans suite du back-end pour les mettre dans des registres.
Mettre le code intermédiaire en forme canonique revient donc à effectuer un dernier travail sémantique sur le code intermédiaire. Réaliser ce travail dans une phase séparée simplifie à la fois le générateur de code intermédiaire et la sélection d’instructions. Sur le code canonique, la sélection d’instruction sera libre d’arranger le code des expressions comme elle l’entend, elle se contentera de respecter la contrainte d’ordre évidente exprimée par la liste d’instructions qu’elle reçoit en argument.
On peut exprimer la canonisation (et la linéarisation du code) par un ensemble de règles de réécriture du code intermédaire. Les règles de transformation des expressions se notent e → s ⊕ c et se lisent, une expression e se tranforme en un code (une liste d’instructions) canonique s et une expression canonique résiduelle c. Des règles possibles sont données par la figure 6.9. Dans cette figure t désigne un temporaire frais. La règle la plus intéressante est de loin celle des appels de fonction.
Const _ → ⊕ Const _
Temp _ → ⊕ Temp _
Name _ → ⊕ Name _
e → s ⊕ c Mem e → s ⊕ Mem c
e1 → s1 ⊕ c1 e2 → s2 ⊕ c2 Bin (op, e1, e2) → s1 ; Move (t, c1) ; s2 ⊕ Bin (op, Temp t, c2)
e1 → s1 ⊕ c1 ⋯ en → sn ⊕ cn Call (f,[e1 ; … ; en]) → s1 ; Move (t1, c1) ; … ; sn ; Move (tn, cn) ; Move (tn+1, Call (f,[Temp t1 ; … ; Temp tn])) ⊕ Temp tn+1
(La traduction de ces règles en un programme Caml, même truffé de concaténations de listes, est un exercice intéressant.)
Ces règles respectent bien l’ordre d’évaluation des expressions et tous les appels de fonctions sont « remontés ». Mais ces règles en font beaucoup trop : il n’y a plus d’arbres du tout, enfin presque plus, les arbre penchent maintenant systématiquement à droite ! Il faut en fait adopter des règles plus fines pour les opérateurs et les fonctions. Considérons maintenant la règle des opérateurs, cette règle introduit un temporaire frais et une instruction Move , uniquement parce que nous devons évaluer c1 avant d’évaluer e2. On dit en général que deux expressions commutent quand l’évaluation de l’une et de l’autre peuvent être effectuées dans n’importe quel ordre, sans perturber la sémantique. Or si nons savons que e1 et e2 commutent, nous voudrions bien évaluer c1 après l’exécution de s2 c’est à dire adopter cette règle :
|
Il semble intuitivement clair qu’exécuter s1 (une partie de e1) puis s2 (une partie de e2), puis évaluer c1 et c2 (ce qui reste de e1 et e2) dans n’importe quel ordre doit être possible, si e1 et e2 peuvent justement être évalués dans « n’importe quel ordre ».
Mais penchons nous de plus près sur la correction de cette règle. Les expressions c1 et c2 sont ultra-canoniques : ce ne sont jamais des appels de fonction (plus généralement, elle ne font pas d’effets de bord) et elles commutent certainement entre elles. On peut donc envisager sereinement une expression Bin (op, c1, c2) dans tous les cas. La commutation de e1 et e2 se réduit donc maintenant à savoir si on peut évaluer c1 après l’exécution de s2, au lieu du contraire commandé par la sémantique. Il est facile de fournir des approximations, d’abord triviales (s2 est vide, ou c1 est une constante), puis un peu plus raffinées en confrontant les temporaires lus par c1 aux temporaires écrits par s2, et en considérant aussi si c1 lit la mémoire et si s2 écrit dans la mémoire. La règle devient en tout cas :
|
Je propose le code de la figure 6.10 pour réaliser la canonisation des expressions.
(* test de commutation simple *) let commute s c = match s,c with | Seq [],_ -> true | _,(Name _ |Const _) -> true (* vive les or-pats *) | _,_ -> false (* Autant profiter de Seq *) let stm_append s1 s2 = match s1, s2 with | Seq [],_ -> s2 | _,Seq [] -> s1 | _,_ -> Seq [s1 ; s2] (* Écrit selon les règles de réécriture *) let rec canon_exp e = match e with | (Name _ | Temp _ | Const _) -> Seq [], e | Mem e -> let s,c = canon_exp e in s, Mem e | Bin (op, e1, e2) -> let s1,c1 = canon_exp e1 and s2,c2 = canon_exp e2 in if commute s2 c1 then stm_append s1 s2, Bin (op, c1, c2) else let t = Gen.new_temp () in stm_append s1 (stm_append (Move_tmp (t, c1)) s2), Bin (op, Temp t, c2) | Call (f,args) -> let s, cs = canon_exps args in let t = Gen.new_temp () in stm_append s (Move_temp (t, Call (f, cs))), Temp t and canon_exps es = ... (* généralisation du cas « Bin » *)
Notons que, dans le cas de Pseudo-Pascal, l’approximation triviale suffit pour ne pas toucher aux arbres qui ne contiennent pas d’appel de fonction, et c’est bien là l’essentiel. Enfin, la règle affinée par la commutation se généralise aux appels de fonction. Ici, il faudra vérifier que l’argument canonique ci commute avec le code canonique si+1 ; … ; sn.
La canonisation donne aussi lieu à des règles à appliquer aux
instructions, mais elles sont bien moins intéressantes. Elles
reviennent à remplacer s1 ; Seq [s2 ; … s3] ; s4 par
s1 ; s2 ; … ; s3 ; s4 (on note au passage les libertés prises avec
les notations des listes…), ainsi qu’à appeler la canonisation
des expressions.
Pour clarifier un peu voici une fonction flatten_stm possible
qui supprime les Seq de l’instruction passée en argument :
| let rec do_noseq i k = match i with | Seq is -> do_noseqs is k | i -> i::k and do_noseqs is k = match is with | [] -> k | i::rem -> do_noseq i (do_noseqs rem k) let flatten_stm i = do_noseq i [] let flatten_stms is = do_noseqs is [] |
On pourrait assez logiquement appeler flatten_stm sur le
résultat d’une fonction canon_stm, de type stm -> stm,
chargée d’appeler la fonction
canon_exp de la figure 6.10).
On pourrait aussi mélanger supression des
instructions Seq et canonisation mais ce serait moins
clair et guère plus efficace.
Une fois canonisé (et mis à plat), le code intermédiaire comprend encore une instruction étrange : l’instruction de test-and-branch Cjump , qui spécifie les deux étiquettes où brancher. En langage machine les instructions test-and-branch spécifient seulement l’etiquette de branchement en cas de condition valide, autrement l’execution du code se poursuit en séquence. Cette contrainte est parfaitement expressible dans le code canonique, il suffit d’imposer que l’étiquette « condition invalide » suive toujours le test-and-branch :
|
Obtenir cette situation peut entraîner de nier le test relop, si c’est lt qui suit l’instruction Cjump, ou même d’introduire une nouvelle étiquette et un saut vers lf, si ni lt ni lf ne suivent le Cjump.
De fait, avec ce test-and-branch bi-étiquette, nous avons introduit une complication, complication qui sert surtout à autoriser l’analyse et la transformation du code, ou plus précisément du flot de son exécution (control flow).
Par définition, un bloc de base (basic block) est une suite (maximale) d’instructions qui est nécessairement exécutée de son début à sa fin. Lorsque l’on ne s’interesse qu’au flot de l’exécution on peut voir un bloc de base comme une grosse instruction (pensez-y deux minutes). En première approximation les blocs de base commencent par une étiquette et se terminent par un saut (conditionnel ou pas) et ne contiennent ni étiquette ni saut. Une étiquette isolée n’est pas un problème, car on peut moralement la faire précéder d’un saut vers elle-même. La génération de code intermédiaire provoque d’ailleurs fréquemment cette situation dans le cas par exemple de la compilation de la conditionnelle. Pour expliciter les blocs de base, il suffit de parcourir une liste d’instructions et de la découper dès que l’on voit une construction qui marque une limite inférieure de bloc (figure 6.11).
type basic_block = {enter:Gen.label ; mutable succ:stm ; body:stm list} (* Poursuivre la construction d'un bloc commençant par l'étiquette cur_lab suivie des instructions cur_ydob (à l'envers) *) let rec in_block f cur_lab cur_ydob = function (* Une étiquette termine le bloc *) | Label lab::rem -> let r = in_block f lab [] rem in {enter=cur_lab ; succ=Jump lab ; body=List.rev cur_ydob}::r (* Un saut termine le bloc *) | (Jump _ | Cjump (_,_,_,_,_)) as stm::rem -> let r = start_block f rem in {enter = cur_lab ; succ = stm ; body = List.rev cur_ydob}::r (* Tout autre instruction est à ajouter au bloc *) | stm::rem -> in_block f cur_lab (stm::cur_ydob) rem (* Dernier bloc, ajouter un saut vers l'épilogue *) | [] -> [{enter = cur_lab ; succ = Jump (Frame.frame_return f) ; body = List.rev cur_ydob}] (* Commencer un bloc ici *) and start_block f stms = match stms with | Label lab::rem -> in_block f lab [] rem | _ -> assert false (* code mal généré *) let code_to_blocks f code = in_block f (Frame.frame_name f) [] code
Notez la régularité de la représentation : les étiquettes du prologue et de l’épilogue marquent les deux extrêmités de la liste d’instructions découpée en blocs.
Mais un processeur n’exécute pas une suite de blocs de bases. On doit
lui présenter une suite d’instructions, que nous pouvons bien voir
alors comme une suite de blocs de base mis bout-à-bout.
Le code était d’ailleurs bien dans cet état avant de passer par la
moulinette code_to_blocks de la figure 6.11.
Et nous pouvons bien imaginer une fonction réciproque
block_to_code qui défait le
travail (figure 6.12, qui utilise fold_right du
module List).
let blocks_to_code blocks = match blocks with | {body=stms ; succ=stm}::rem -> stms @ stm :: List.fold_right (fun {enter=lab; body=stms; succ=stm} r -> Label lab::stms @ stm :: r) rem [] | _ -> assert false
Notez que la première étiquette du premier bloc est enlevée, on suppose donc qu’il s’agit toujours de l’étiquette ajoutée précedemment. En revanche, on laisse en place les sauts vers l’épilogue (on pourra enlever un éventuel saut final vers l’épilogue plus tard).
Pourquoi se fatiguer autant ? La structure en liste des blocs de bases n’exprime en fait rien de particulier. Les blocs sont bien mieux organisés selon un graphe de flot (d’exécution) dont les sommets sont les blocs. Il y a un arc du bloc b1 au bloc b2 quand l’exécution peut à la fin de b1 se poursuivre par l’exécution de b2. Le graphe de flot représente toutes les exécutions possible d’un bout de code. Cette représentation est idéale pour les optimisations du contrôle. Prenons l’exemple assez simple de deux conditionnelles imbriquées et
| If (Bin (op1, e1, e2), st, If (op2, e3, e4, sft, sff)) |
En compilant, selon notre schéma simple, on obtient une belle pagaille d’étiquettes et de sauts :
|
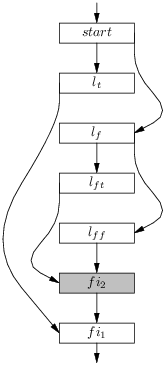
La situation s’éclaircit en peu si on regarde le graphe de flot correspondant (à gauche dans la figure 6.13)
Dans cette figure, les blocs sont désignés par leurs étiquettes d’entrée et l’ordre de présentation initial des blocs est conservée. Les flèches entrante et sortante disent le début et la fin de n’importe quelle exécution. En machine on peut représenter un graphe de flot par la liste des sommets (une liste de Gen.label) et une table de hachage (module Hashtbl) qui associe des blocs aux sommets. On retrouve alors facilement les successeurs d’un sommet (figure 6.14).
let blocks_to_flowgraph blocks = let t = Hashtbl.create 17 in let labs = List.map (fun b -> let lab = b.enter in Hashtbl.add t lab b ; lab) blocks in labs, t let get_block t lab = Hashtbl.find t lab let get_succ b = match b.succ with | Jump lab -> [lab] | Cjump (_,_,_,lab1,lab2) -> [lab1 ; lab2] | _ -> assert false
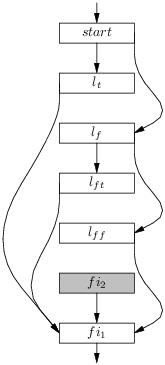
Une trace est une exécution possible du code, c’est à dire un parcours possible de l’entrée à la sortie du graphe de flot, ici nous avons en tout trois traces : (start, lt, fi1), (start, lf, lft, fi2, fi1) et (start, lf, lff, fi2, fi1). Mais le bloc fi2 (grisé) est « vide », c’est à dire qu’il ne contient pas d’instruction et qu’une seule flèche en sort. On peut donc l’enlever de toutes les traces sans rien changer à l’effet de ces traces. Cela revient à court-circuiter le bloc fi2 dans le graphe de flot. On obtient le graphe de droite de de la figure 6.13, on notera que le bloc fi2 n’est plus dans aucune trace, il n’est plus atteignable à partir de l’entrée, il constitue du code mort. Le court-circuitage des blocs vides revient à enlever des sauts vers les sauts, une optimisation qui est toujours gagnante. Il est assez facile à réaliser, il suffit de parcourir les sommets du graphe de flots, on suit alors chaque arc sortant jusqu’à trouver un bloc non-vide et on remplace l’arc sortant par un arc vers ce bloc non-vide. Le code donné à la figure 6.15 réalise cette opération sur une liste de blocs acompagnée de la table de hachage produite à la figure 6.14
let rec shorten_lab t lab = try let b = get_block t lab in match b with | {body=[]; succ=Jump olab} -> shorten_lab t olab | _ -> lab with | Not_found -> lab let shorten_block t b = match b.succ with | Jump lab -> b.succ <- Jump (shorten_lab t lab) | Cjump (op,e1,e2,lab1,lab2) -> b.succ <- Cjump (op, e1, e2, shorten_lab t lab1, shorten_lab t lab2) | _ -> () let shorten_blocks t blocks = List.iter (shorten_block t) blocks
(Notez que ce code boucle si il y a des cycles de blocs vides dans le graphe de flot.)
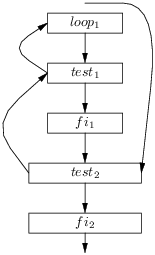
Les graphes de flot autorisent des optimisations plus complexes. Prenons l’exemple simple du code généré pour la boucle while :
|
On obtient le graphe de flot :
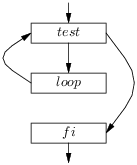
Ici nous avons une infinité de traces, commençant par test, suivi d’un nombre arbitraire (au point de pouvoir être nul) d’enchaînements de loop et de test, suivis d’un fi. Nous pouvons parfaitement changer l’ordre de présentation des blocs et obtenir le graphe de flot suivant, équivalent au précédent (il admet les mêmes traces, en fait c’est le même graphe dessiné autrement) :
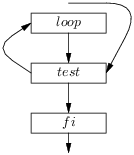
Retraduisons ensuite la liste de blocs en code :
|
Appliquons la simplification évidente de supprimer le saut dans Jump test ; Label test (mais pas l’étiquette).
|
Le code final est presque certainement meilleur (et sans doute pas pire) que le code de départ. En effet, nous avons ameilloré l’exécution d’une infinité de traces en supprimant un saut par passage dans la boucle. Du point de vue des traces, on peut dire que le corps de boucle ainsi présenté loop, test est dans sa trace.
De façon plus générale, en considérant des boucles imbriquées, on conçoit l’importance de présenter les boucles dans leur trace (figure 6.16). Malheureusement c’est assez difficile à réaliser sur un graphe de flot arbitraire et encore plus si le graphe est issu d’un langage qui possède goto.
Je présente donc un algorithme plus simple de production d’un arrangement. Cet algorithme construit un ensemble de traces T, en construisant gloutonnement des traces t et un ensemble de blocs atteignables A.
(Je ne suis vraiment pas malin, il y a un goto dans cet algorithme informel). L’algorithme a l’avantage d’éliminer le code mort qui n’est pas atteignable à partir de l’entrée (ie. qui n’est dans aucune trace). Cela paraît bien excessif, mais cela arrive (en C, mélange de break, return, etc.). Par ailleurs le court-circuitage des blocs vides introduit du code mort. Le petit nettoyage qui élimine les blocs vides court-circuités en même temps que tout le code mort a un petit air élégant. L’idée qui est derriere la démarche gloutonne est que si les traces sont les plus longues possibles, alors l’exécution aura tendance à se faire plutôt en séquence et que donc on pourra supprimer des sauts.
Mais en fait je n’aime pas du tout cet algorithme qui saccage l’ordre de présentation des traces. En effet, comme Pseudo-Pascal est structuré (pas de goto) on peut dès la génération de code produire un arrangement convenable des traces des boucles. Il suffit de compiler la boucle while selon le schéma qui produit le bon arrangement du graphe de flot (que nous avions retrouvé à partir du bon arrangement). Même si on n’utilise pas ce schéma (contestable à cause de problèmes d’alignement des adresses de code), les boucles imbriquées seront correctement placées les unes par rapport aux autres, reflétant la bonne structuration présente dans le code source. Ensuite, on peut se contenter de supprimer les blocs inatteignables de la liste initiale de blocs, sans en changer l’ordre. C’est assez facile à faire, on calcule l’ensemble des sommets atteignables en un parcours du graphe de flot en profondeur d’abord, puis on ne retient que les blocs atteignables (figure 6.17, qui emploie la fonction filter du module List).
let remove_unreachable t labs = let rec dfs r lab = if mem lab r then r else let r = add lab r in if Hashtbl.mem t lab then let succ = get_succ (get_block t lab) in List.fold_left dfs r succ else r in match labs with | start::rem -> let reach = dfs empty start in let labs = start::List.filter (fun lab -> mem lab reach) rem in List.map (get_block t) labs | _ -> assert false
Ce code suppose donnée une réalisation des ensembles d’étiquettes (empty est l’ensemble vide, mem teste l’appartenance, add ajoute une étiquette à un ensemble).
Une fois les blocs de base réarrangés on peut les retransformer en
code à plat, en leur appliquant la fonction blocks_to_code de
la figure 6.12.
Il reste ensuite à se débarrasser des sauts vers une étiquette
immédiatement succesive et à garantir que les test-and-branch sont
bien suivis de l’étiquette correspondant au cas false du test.
On réalise ce dernier petit travail par une optimisation « trou
de serrure » (peephole), particulièrement facile à programmer
en Caml par un filtrage de la liste d’instructions
(figure 6.18, le code est un peu compliqué par la gestion
des sauts vers l’épilogue).
let neg = function | Req -> Rne | Rne -> Req | Rle -> Rgt | Rge -> Rlt | Rlt -> Rge | Rgt -> Rle | _ -> assert false let rec peephole f = function (* Cas particulier des sauts vers l'épilogue *) | [Cjump (relop, e1, e2, lab1 , lab2)] when lab1 = Frame.frame_return f -> [Cjump (neg relop, e1, e2, lab2 , lab1)] | [Cjump (relop, e1, e2, lab1 , lab2)] when lab2 = Frame.frame_return f -> [Cjump (relop, e1, e2, lab1 , lab2)] | [Jump lab] when lab=Frame.frame_return f -> [] (* Garantir que « Label l2 » suit immédiatement *) | Cjump (relop, c1, c2, l1, l2) :: t -> begin match t with | Label l3 :: t3 when l1 = l3 -> Cjump (neg relop, c1, c2, l2, l1) :: Label l3 :: peephole f t3 | Label l3 :: t3 when l2 = l3 -> Cjump (relop, c1, c2, l1, l2) :: Label l3 :: peephole f t3 | _ -> (* cas embêtant, il faut ajouter une nouvelle étiquette *) let l4 = Gen.new_label () in Cjump (binop, c1, c2, l1, l4) :: Label l4 :: Jump l2 :: peephole f t end (* Saut inutile *) | Jump l1 :: Label l2 :: t when l1 = l2 -> Label l2 :: peephole f t (* Cas normaux *) | h :: t -> h :: peephole f t | [] -> []
Il reste ensuite à mettre tout le code ensemble, production des blocs (figure 6.11) et du graphe de flot (figure 6.14), court-circuitage des blocs vides (figure 6.15), suppression des blocs inatteignables (figure 6.17), retour au code (figure 6.12), et finalement nettoyage (figure 6.18). Ce que fait le code de la figure 6.19.
let opt_trace f c = let blocks = code_to_blocks f c in let labs,t = blocks_to_flowgraph blocks in shorten_blocks t blocks ; let blocks = remove_unreachable t labs in peephole f (blocks_to_code blocks)